Cómo construir un sistema de scoring de empresas de grado de inversión con Make y datos alternativos
Descubre cómo usar Make para transformar datos alternativos brutos en un sistema de scoring de empresas estructurado y explicable para inversión, desarrollo corporativo o priorización de go-to-market (GTM).  Esto te da el número total de nuevas vacantes publicadas en los últimos 90 días. *Paso 5: Identificar la actividad de contratación de perfiles sénior
La contratación de liderazgo suele indicar crecimiento estratégico.PredictLeads → List Job Openings (90 days)
Vuelve a usar la misma consulta de 90 días. *Filter
Conserva solo los roles en los que: * seniority ∈ manager, director, head, VP, executive*
Array Aggregator + Set variable
Crea: senior_roles_90d = length(aggregated_senior_jobs)Paso 6: (Opcional) Añadir impulso a corto plazo
Repite el mismo patrón con una ventana de 30 días: jobs_30d = ofertas de empleo detectadas por primera vez en los últimos 30 días Esto te permite medir la aceleración de la contratación.Paso 7: Actualizar Google Sheets (una sola escritura)
Al final del escenario: Añade Google Sheets → Update row Haz coincidir las filas por: * domainActualiza: * jobs_90d * jobs_30d * senior_roles_90d * last_scored_at
Esto garantiza que todas las métricas se registren en la misma fila.
¿Qué ventajas ofrece?
Este enfoque garantiza: * Sin problemas de concurrencia * Sin actualizaciones parciales * Números completamente explicables * Depuración sencilla * Fácil de ampliarCada conjunto de datos se procesa de forma independiente, y Make actúa como capa de orquestación.
Ampliar el flujo de trabajo con más señales
Una vez que el bloque de empleos esté estable, puedes añadir fácilmente:Eventos de noticias
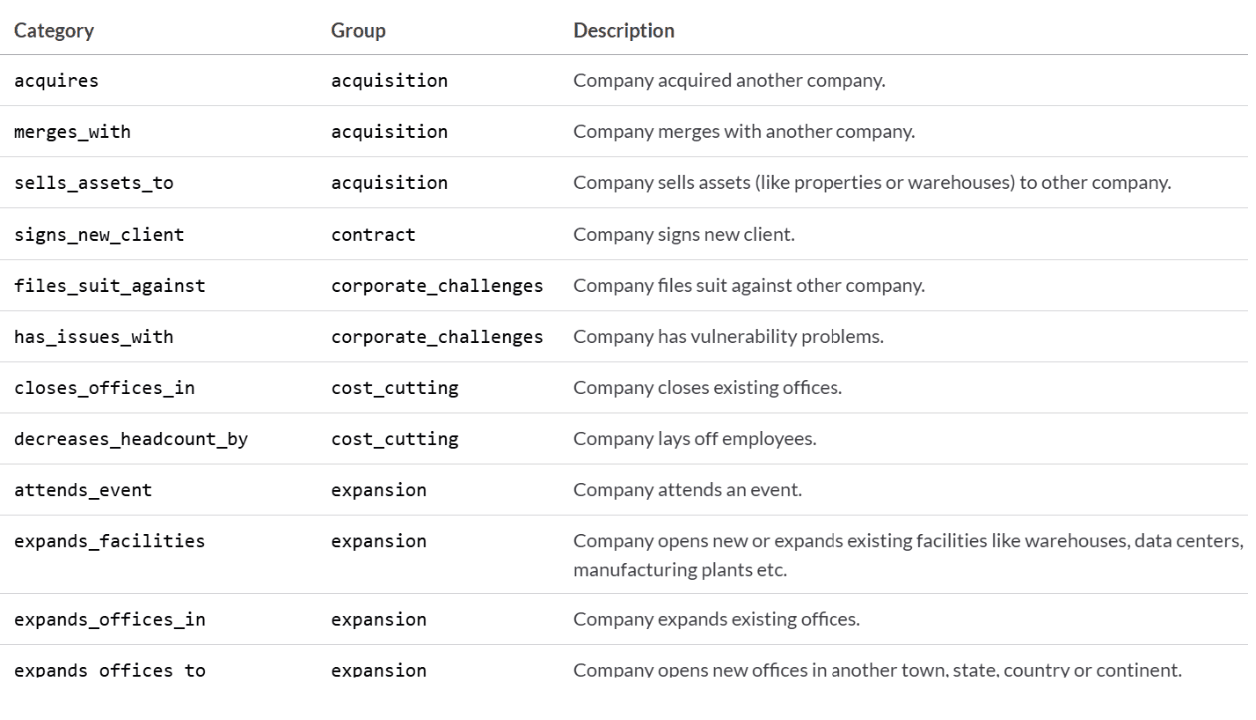
* Contar eventos de alta confianza * Detectar señales negativas como despidos!GP_PredictLeads_Table 2 Todas las categorías se pueden encontrar aquí.
{kind=link}
Adopción de tecnología
* Medir el uso de una pila tecnológica moderna * Detectar cambios recientes en herramientasCada señal sigue el mismo patrón: Fetch → Filter → Aggregate → Variable !Guest post_Predictleads_Table
{kind=link}