Como construir um sistema de score de empresas de nível institucional com Make e dados alternativos
Descubra como usar o Make para transformar dados alternativos brutos em um sistema estruturado e explicável de score de empresas para investimentos, desenvolvimento corporativo ou priorização de go-to-market.  Isso fornece o número total de novas vagas abertas nos últimos 90 dias. *Etapa 5: Identificar atividade de contratação de liderança
Contratações de liderança muitas vezes sinalizam crescimento estratégico.PredictLeads → List Job Openings (90 days)
Reutilize a mesma consulta de 90 dias. *Filter
Mantenha apenas cargos em que: * seniority ∈ manager, director, head, VP, executive*
Array Aggregator + Set variable
Crie: senior_roles_90d = length(aggregated_senior_jobs)Etapa 6: (Opcional) Adicionar impulso de curto prazo
Repita o mesmo padrão com uma janela de 30 dias : jobs_30d = vagas abertas vistas pela primeira vez nos últimos 30 dias Isso permite medir a aceleração da contratação.Etapa 7: Atualizar o Google Sheets (uma única gravação)
No final do cenário: Adicione Google Sheets → Update row e faça a correspondência das linhas por: * domainAtualize: * jobs_90d * jobs_30d * senior_roles_90d * last_scored_at
Isso garante que todas as métricas sejam gravadas na mesma linha.
O que isso lhe dá
Esta abordagem garante: * Sem race conditions * Sem atualizações parciais * Resultados totalmente explicáveis * Fácil de depurar * Fácil de expandirCada dataset é processado de forma independente, e o Make atua como camada de orquestração.
Expandindo o fluxo de trabalho com mais sinais
Assim que o bloco de vagas estiver estável, você pode adicionar facilmente:Eventos de notícias
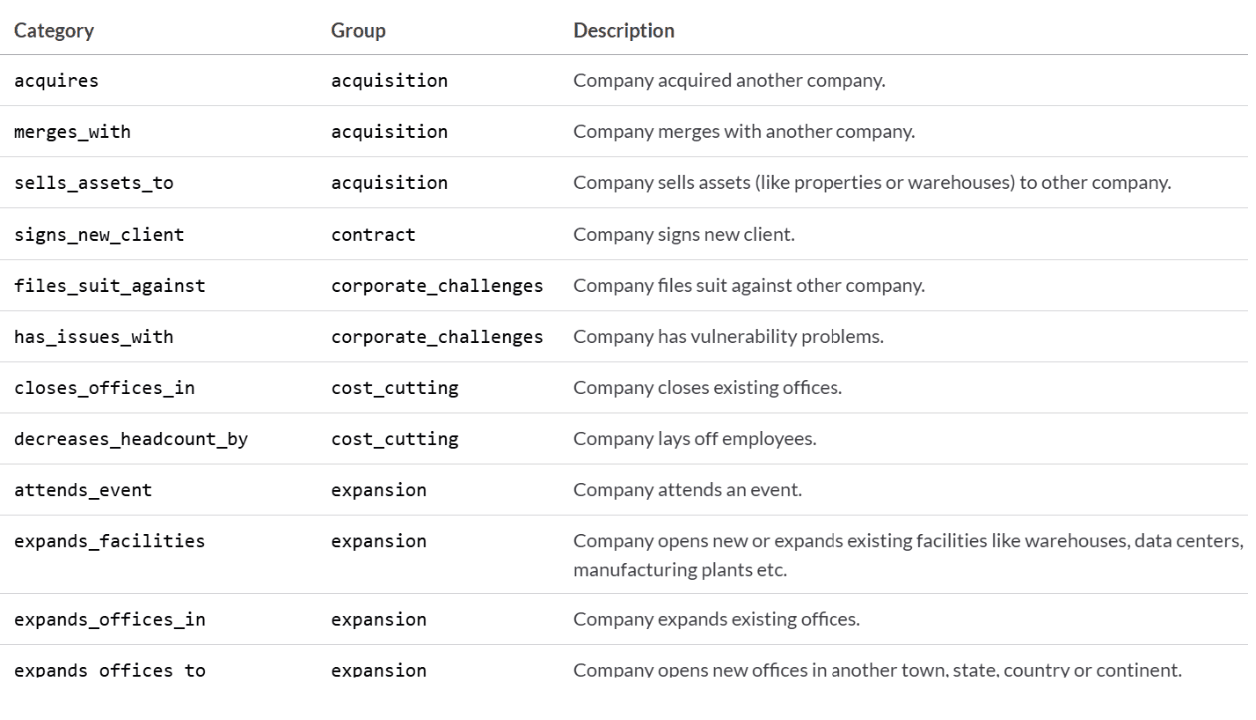
* Contabilizar eventos com alta confiabilidade * Detectar sinais negativos como demissões!GP_PredictLeads_Table 2 Todas as categorias podem ser encontradas aqui.
{kind=link}
Adoção de tecnologia
* Medir o uso de uma stack de tecnologia moderna * Detectar mudanças recentes na stack de ferramentasCada sinal segue o mesmo padrão: Buscar → Filtrar → Agregar → Variável !Guest post_Predictleads_Table
{kind=link}